Voting Machines
In his seminal book, Expert Political Judgment, Philip Tetlock observes that “partisans across the opinion spectrum are vulnerable to occasional bouts of ideologically induced insanity.” Ideological partisans fall in love with grand theories of history, and then they act over-confidently based on inaccurate forecasts.
Growing up in Zimbabwe under the Marxist dictatorship of Robert Mugabe, I experienced more than my fair share of ideologically induced insanity. And I spent my years at Harvard and the University of Chicago studying politics and economics, attempting to discern how to avoid these types of disasters.
Tetlock’s work provides invaluable insight. He finds that experts are no better than non-experts at making forecasts about the future—a convincing argument for democracy. And he finds that the best forecasters are skeptical of grand theories, draw from multiple information sources, and are humble about their knowledge—a convincing case for a free political system.
These findings also provide good insight into making investment decisions. At Verdad, our investment process uses multiple methodologies: linear regression models, machine learning algorithms, and qualitative judgment. By introducing multiple perspectives, both quantitative and qualitative, we believe we improve the accuracy and quality of the decisions we make.
We are very excited about the model we introduced last week that looks for errors in factor models. We call this system our “probability of being wrong.” And we showed that for 90% of stocks, the higher the probability of being wrong, the higher the expected return. But in the most extreme 10% of stocks, our model is good at identifying problematic situations. You can see this in the chart below.
Figure 1: Out-of-Sample Returns by Decile of Probability of Being Wrong (Jul 1997 to Jun 2018)

Sources: S&P Capital IQ and Verdad research
We were very excited to find that our machine learning model could identify these problem stocks. But machine learning can be inscrutable, as it functions by building thousands of probability trees and finding patterns among them. The best way to understand what the model achieves is by looking at examples. Below are the two European stocks that our machine learning model gives the highest probability of being wrong.
Figure 2: Examples of Potential Extreme Errors (March 2019)
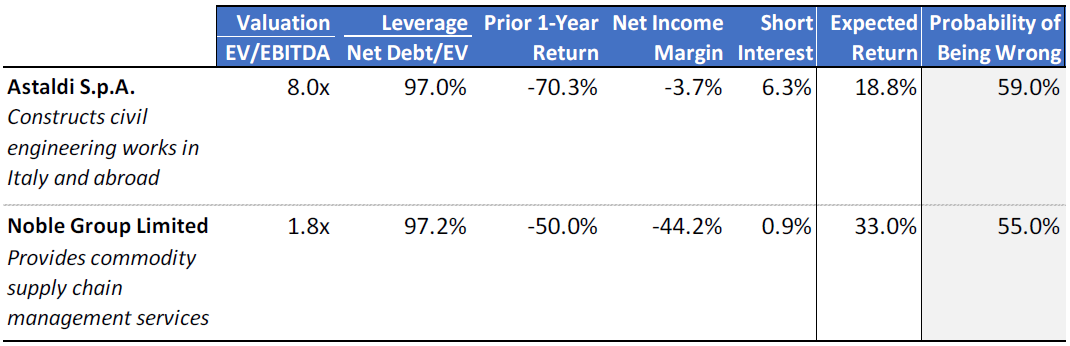
Sources: S&P Capital IQ and Verdad research
Astaldi and Noble Group have expected returns of 19% and 33% in a linear model. But at 59% and 55% respectively, our machine learning model rates the probability of being wrong in owning Astaldi or Noble Group well above the 50% threshold that has historically been detrimental to returns, as we demonstrated last week. A quick look at Astaldi’s website reveals that the company might be on a path to bankruptcy. Astaldi’s debt has an abysmal “D” rating from S&P and a “Ca” rating from Moody’s with a negative outlook. Fitch rates the company’s debt as “Restricted Default,” which is one step away from the worst rating of “Default” that’s reserved for companies in bankruptcy. Meanwhile, an online search of Noble Group shows that the company is in restructuring and is also under investigation for accounting fraud.
Looking at the stocks this model was identifying as dangerous, we immediately understood how powerful a tool we’d built. A human analyst reviewing these stocks would decide to pass after a few minutes of research. With the probabilities of being wrong, it only takes a few seconds to reach the same conclusion.
So how should the extreme probabilities of being wrong be used in an investment process?
We believe in letting different models vote on the stocks in our universe, allowing competing perspectives to flourish and collaboratively identify the best and worst stocks. One model predicts the probability of debt paydown for every stock in our universe. A second model combines these deleveraging probabilities with other linear factors like value, profitability, and momentum, and then ranks stocks according to how they score on all factors. And a third model can anticipate forecast errors.
Together, these models function as an ensemble. Each model will correct for the mistakes of the other in the extremes of the stock universe. Figure 3 illustrates how our quantitative models are arranged into an assembly line of voting machines for stock selection.
Figure 3: Structure of Voting Machines

Source: Verdad research
Our machine learning ranking model incorporates inputs from the first three models into its decisions. Figure 4 illustrates the input variables that are most important to this ranking model. The bars reflect each variable’s effect in improving the model’s ability to accurately rank stocks on new data (out of sample).
Figure 4: Variable Importance in Machine Learning Ranking Model (Jul 1997 to Jun 2018)

Sources: S&P Capital IQ and Verdad research
Unsurprisingly, the most important variable is the probability of being wrong. The second most important variable is the linear model’s expected return. The next five variables are all related to the most pertinent questions a human analyst would ask when evaluating stocks in our target universe. How much cash flow does the company generate? Is the company both cheap and levered? How cheap is the stock? Is the company likely to pay down debt? How much debt does the company have overall?
As we wrote previously, any reliable machine learning approach in finance should build on traditional linear models, not replace them. It should also deliver exposure to sensible factors at the end of the day. The results in the figure above meet both of these criteria.
How does this translate into improved stock returns? We can compare the performance of our linear factor model—the most common quantitative tool for stock selection—to the results of our ensemble model. Figure 5 shows the baseline out-of-sample returns from ranking according to the original linear model. Data is from the US and Europe from 1997 to 2018. This sample was not shown to any of our machine learning models during training, so it is useful for testing the models’ performance on new data.
Figure 5: Baseline Ranking Results from Linear Model (Jul 1997 to Jun 2018)

Sources: S&P Capital IQ and Verdad research
We then looked at how our ensemble model—which integrates these linear ranks with our machine learning ranks to produce a combined sorting—would improve these results. Figure 6 shows the out-of-sample performance of the ensemble.
Figure 6: Out-of-Sample Ranking with Ensemble Model (Jul 1997 to Jun 2018)

Sources: S&P Capital IQ and Verdad research
Relative to the linear model, this ensemble model improves returns by about 3% in the Top 40 ranked names—a massive improvement.
Based on this evidence, it seems clear that incorporating debate and disagreement—allowing multiple perspectives to compete against each other—produces better outcomes in quantitative investing, just as it does in politics.