A Sharper Signal Amid the Noise
Deleveraging is both important and predictable, making it fertile ground for better forecasts.
By: Brian Chingono
Investing, like any productive endeavor, requires efficient allocation of resources. Where should investors allocate most of their time, given the myriad options that are calling for attention, from Fed announcements to earnings updates to analyst reports? And even after narrowing down the most important sources of information, which specific data points should investors pay most attention to?
A simple framework would be to organize forecasting tasks into a 2x2 matrix with “Importance” on one axis and “Predictability” on the other axis. A straightforward implication of this matrix would be that investors should focus the vast majority of their time on forecasting outcomes that are both important for returns and have a meaningful level of predictability in the first place.
An example of this framework is illustrated in the table below. Perhaps the most controversial aspect of this table is that predicting the FIFA World Cup winner is in the “Low Importance” column. Rest assured, this is only in the context of investment outcomes. In almost any other context, we think the World Cup should rank in the “High Importance” column! It may also come as a surprise that forecasting earnings growth is placed in the “Low Predictability” row. As we have written before, earnings are an important component of investor returns. But earnings growth has little persistence beyond chance, and even well-informed analysts have a limited ability to sort companies into the correct growth quintiles. So it’s worth making an effort to estimate future earnings, but we think investors should be cautious about how much confidence they place in those earnings forecasts.
Figure 1: Examples of Forecasting Tasks Ranked by Predictability and Importance for Returns

Source: Verdad research. For illustrative purposes only.
That leaves deleveraging as an example of a forecasting task that we believe is both very important for returns and highly predictable. As we last wrote in 2019, deleveraging can be predicted with around 66% accuracy over a one-year horizon. And the benefits of deleveraging are self-evident: companies that pay down debt mechanically have a higher equity balance and become more resilient to economic shocks, potentially warranting a higher valuation multiple.
Given the importance and predictability of deleveraging, we’ve spent the better part of a year updating the debt paydown model we last shared in 2019 in an effort to increase out-of-sample accuracy beyond the 66% threshold. The updates primarily involved adding higher-frequency versions of the most important input variables (e.g., fundamental changes over the past six months in addition to changes over the past year) and defining input variables in a way that results in more symmetric distributions (because models work better with data that’s closer to a normal distribution).
As before, the objective of the updated model is to forecast deleveraging over a one-year horizon, and outcomes are tagged with a binary indicator where 1 represents companies that reduced their long-term debt over the next year and 0 represents all other outcomes. The updated model was trained on a randomized subsample of CRSP data from 1974 to 2014 (60% of unique companies), and the other 40% of unique companies were held out for out-of-sample testing. This methodology ensures, for example, that if Chevron appears in the training sample, it never shows up in the hold-out sample (and vice versa). When testing the updated model on the hold-out sample, the algorithm estimates a probability for each company that corresponds with its likelihood of paying down debt over the next year. The results of our out-of-sample analysis on US companies since 1974 are below.
Figure 2: Out-of-Sample Deleveraging Results in the US (1974–2014)
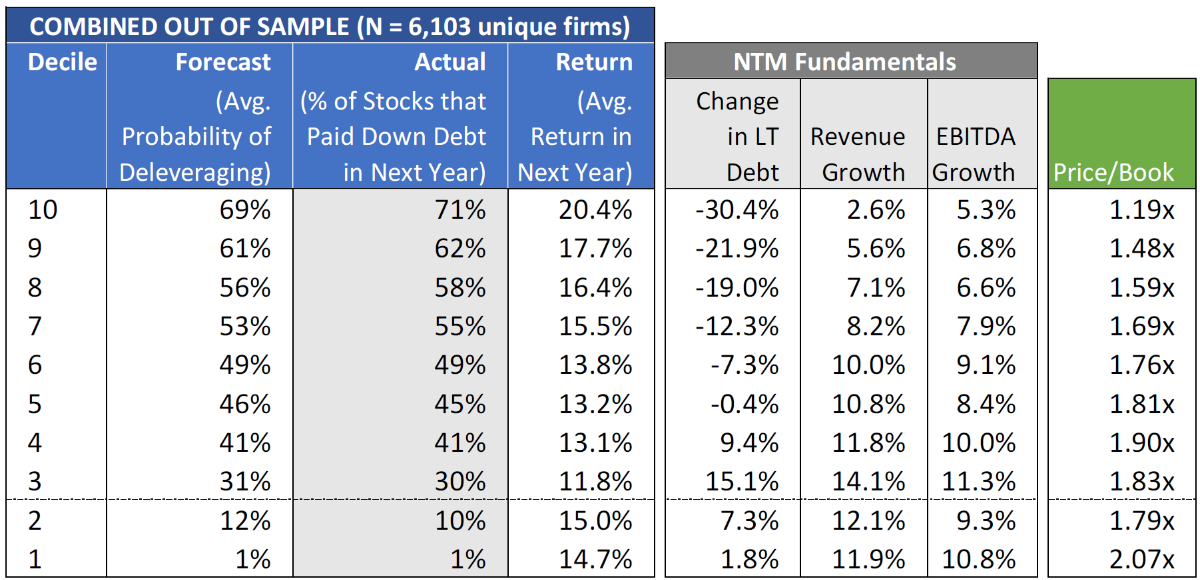
Source: CRSP and Verdad research. Note: Deciles 1 and 2 are primarily net-cash companies
It appears the updated model is achieving its primary objective on brand new data. Forecast accuracy in the top decile of 70.5% is around 4 percentage points higher than the previous 66% threshold. And even though the model was not trained to forecast returns, the companies with the highest deleveraging probability also have the highest average annual returns. The four columns on the right explain why this is the case. Companies with higher deleveraging probabilities pay down a larger portion of their debt over the next year. They also tend to be slower growth companies that are priced at lower valuations (the median Price/Book in Decile 10 is 1.2x versus 2.1x in Decile 1). So the combination of higher equity balances from deleveraging and some multiple expansion from cheap starting valuations contribute to higher returns among companies that are more likely to pay down debt.
Moreover, when the model is evaluated over time, we see that deleveraging is cyclical, with a higher proportion of companies paying down debt when the economy is slowing down. This pattern seems intuitive: when faced with the prospect of slower sales, the responsible thing for CFOs to do would be to batten down the hatches and reduce debt to weather the storm ahead. The figure below illustrates this process among Decile 10 companies that have the highest likelihood of deleveraging, according to our model. The solid line represents actual deleveraging, and we can see spikes in the proportion of companies that pay down debt during recessions.
Figure 3: Cyclicality of Deleveraging in the US (1974–2014)

Source: CRSP and Verdad research
Another important implication of the chart above is that deleveraging outcomes in the top decile remain within a consistent band between 60% and 80% over a 50-year sample that includes a range of macro environments, from inflation spirals to stock market bubbles to financial crises. Through all of the noise, we are pleased to see a clear majority of companies in the highest forecast decile actually paying down debt over the next year. And above all, we are happy to see a four-percentage-point improvement in forecasting accuracy in the model on US out-of-sample data. In a subsequent article, we’ll explore the model’s out-of-sample performance in Europe and also evaluate how the forecasting improvement relates to expected returns.